I've moved! I've really enjoyed using Blogger for my blog, but it didn't integrate with my website in the way I wanted. So I've moved my blog to WordPress, which is now also hosting my site.
When you navigate to www.thinkingtester.com, you'll see not only my blog posts, but also my latest articles, videos, courses, and other free goodies.
The posts on this blog will continue to exist, so your old links will still work; I just won't be adding new content to this page. I'm looking forward to seeing you at Think Like a Tester!
Friday, July 3, 2020
Saturday, June 27, 2020
Book Review: Unit Testing Principles, Practices, and Patterns
It's book review time once again, and this month I read Unit Testing Principles, Practices, and Patterns by Vladimir Khorikov. I thought that a book about unit testing would be pretty dry, but it was really interesting!
Since I am not a developer I don't usually write unit tests, although I have done so occasionally when a developer asks me to help. Being a good tester, I knew to do things like mock out dependencies and keep my tests idempotent, but through this book I discovered lots of things I didn't know about unit testing.

The author has a background in mathematics, and it shows. He is very systematic in his process of explaining good unit test patterns, and each chapter builds upon the previous one. Here are some of the important things I learned from this book:
Since I am not a developer I don't usually write unit tests, although I have done so occasionally when a developer asks me to help. Being a good tester, I knew to do things like mock out dependencies and keep my tests idempotent, but through this book I discovered lots of things I didn't know about unit testing.

The author has a background in mathematics, and it shows. He is very systematic in his process of explaining good unit test patterns, and each chapter builds upon the previous one. Here are some of the important things I learned from this book:
- There are two schools of thought about unit testing: the classical school and the London school. In the classical school, unit tests are not always limited to a single class. The tests are more concerned with units of behavior. Dependencies, such as other classes, don't need to be mocked if they aren't shared. In the London school, unit tests are limited to a single class, and calls to other classes are always mocked, even if they are part of the same code base and not shared with any other code.
- Unit tests should always follow this pattern:
- Arrange- where the variables, mocks, and system under test (SUT) are set up
- Act- where something is done to the SUT
- Assert- where we assert that the result is what we expect
- The Act section of the unit test should only have one line of code. If it has more than one line of code, that probably means that we are testing more than one thing at a time.
- A good unit test has the following characteristics:
- It's protected against regressions- it shouldn't break when you change something unrelated in the code
- It's resistant to refactoring- refactoring the code shouldn't break the test
- It provides fast feedback
- It's maintainable- it's easy for someone to look at the test, see what it's supposed to do, and make changes to it when needed
- Mocks and stubs are both types of test doubles: faked dependencies in tests which are used instead of calling the real dependencies in order to keep the tests fast, resilient, and focused only on the code being tested.
- Mocks emulate outgoing interactions, such as putting a message on a service bus
- Stubs emulate incoming interactions, such as receiving data from a database
- Test doubles should only be used with inter-system communications: calls to something outside the code, like a shared database or an email server. For intra-system communications, where a datastore or class is solely owned by the code, the call shouldn't be mocked or stubbed.
The most interesting thing I learned from the book was that it's really hard to write good unit tests when the code is bad. The author provides lots of examples of how to refactor code in order to make tests more robust. These practices also result in better code! Reading through the examples, I now understand how to better organize my code by separating it into two groups: code that makes a decision, such as function that adds two numbers, and code that acts upon a decision, such as writing a sum to a database.
The author doesn't just write about unit tests in this book; he also describes how to write integration tests, and provides examples of writing tests for interacting with databases.
I learned much more than I was expecting to from this book! Software test engineers will find many helpful ideas for all types of automation code in this book. Software developers will not only improve their unit test writing, but also their coding skills. I recommend it to anyone who would like to improve their test automation.
Saturday, June 20, 2020
Managing Test Data
It's never fun to start your work day and discover that some or all of your nightly automated tests failed. It's especially frustrating when you discover that the reason why your tests failed was because someone changed your test data.
Test data issues are a very common source of aggravation for software testers. Whether you are testing manually or running automation, if you think your data is set the way you want it, and it has been changed, you will waste time trying to figure out why your test results aren't right.

Here are some of the common problems with test data:
Users overwrite each other's data
I was on a team that had an API I'll call API 1. I wrote several automated tests for this API using a test user. API 1 was moved to another team, and my team started working on API 2. I wrote several automated tests for API 2 as well. Unfortunately, I used the same test user for API 2, and this test user needed to have a different email address for API 2 than it did for API 1. This meant that whenever automated tests were run on API 1, it changed the address of the test user, and then my API 2 tests would fail.
Configuration is changed by another team
When teams need to share a test environment, changes to the environment configuration made by one team can impact another team. This is especially common when using feature toggles. One team might have test automation set up with the assumption that a feature toggle will be on, but another team might have automation set up with the expectation that the feature toggle is off.
Data is deleted or changed by a database refresh
Companies that use sensitive data often need to periodically scramble or overwrite that data to make sure that no one is testing with real customer information. When this happens, test users that have been set up for automation or manual testing can be renamed, changed, or deleted, causing tests to fail.
Data becomes stale
Sometimes data that is valid at one point in time becomes invalid as time passes. A great example of this is a calendar date. If an automated test needs a date in the future, the test writer might choose a date a year or two from now. Unfortunately, in a year or two, that future date will become a past date, and then the test will fail.
What can we do to better manage test data? Here are some suggestions:
Use Docker
Using a virtual environment like Docker means that you have complete control over your test environment, including your application configuration and your database. To run your tests, you spin up a virtual machine, run the tests, and destroy the machine when the tests have completed.
Create a fresh database for testing
It's possible to create a brand-new database for the sole purpose of running your test automation. With Windows, this can be accomplished by creating a SQL DACPAC. You can set your database schema, add in only the data that you need for testing, create the database, point your tests to that database, and destroy the database when you are finished.
Give each team their own test space
Even if teams have to share the same test environment, they might be able to divide their testing up by account. For example, if your application has several test companies, each team can get a different test company to use for testing. This is especially helpful when dealing with toggles; one team's test company can have a feature toggled on while another team's test company has that feature toggled off.
Give each team their own users
If you have a situation where all teams have to use the same test environment and the same test account, you can still assign each team a different set of test users. This way teams won't accidentally overwrite one another's data. You can give your users names specific to your team, such as "Sue GreenTeamUser".
Create new data each time you test
One great way to manage test data is to create the data you need at the beginning of the test. For example, if you need a customer for your test, you create the new customer at the beginning of your test suite, use that customer for your tests, and then delete the customer at the end of your tests. This ensures that your test data is always exactly the way you want it, and it doesn't add bloat to the existing database.
Use "today+1" for dates in the future
Rather than choosing an arbitrary date in the future, you can get today's date, and then use an operation like DateAdd to add some interval, like a day, month, or year, to today's date. This way your test date will always be in the future.
Working with test data can be very frustrating. But with some planning and strategy, you can ensure that your data will be correct whenever you run a test.
Saturday, June 13, 2020
Why We Test
Most software testers, when asked why they enjoy testing, will say things like:

- I like to think about all the ways I can test new features
- It's fun to come up with ways to break the software
- I like the challenge of learning how the different parts of an application work
I certainly agree with all of those statements! Testing software is fun, creative, and challenging.
But this is not WHY we are testing. We test to find out things about an application in order to ensure that our end users have a good experience with it. Software is built in order to be used for something; if it doesn't work well or correctly, it is not accomplishing its purpose.

For example:
- If a mobile app won't load quickly, users will stop using it or delete the app from their phone
- If a financial app has a security breach, they'll lose customers and may even be sued for damages
- If an online store has a bug that keeps shoppers from completing their purchases, the company will lose out on sales
There are even documented cases of people losing their lives because of problems with software!
So while it's fun to find bugs, it's also critically important. And it's even more important to remember that the true test of software is how it behaves in production with real users. Often testers keep their focus on their test environment, because that's where they have the most control over the software under test, but it's crucial to test in production as well.
I have seen situations where testers only tested a new feature in their test environment, and then were totally surprised when users reported that the feature didn't work at all in production! This was because there were environment variables that were hard-coded to match the test environment. The feature was released to production, and the testers didn't bother to check it.
Having things "work" in production is only one facet of quality, however. We also need to make sure that pages load within a reasonable amount of time, that data is saved correctly, and that the system behaves well under times of high use.
Take a moment to think about the application you test. In production:
Saying "But it worked in the test environment" is the tester's equivalent of the developer saying "But it worked on my machine". It's fun to test and find bugs. It's fun to check items off in test plans. It's fun to see test automation run and pass. But none of those things matter if your end user has a poor experience with your application.
Take a moment to think about the application you test. In production:
- Is it usable?
- Is it reliable?
- Is the user's data secure?
- Do the pages load quickly?
- Are API response times quick?
- Do you monitor production use, and are you alerted automatically if there's a problem?
- Can you search your application's logs for errors?
Saying "But it worked in the test environment" is the tester's equivalent of the developer saying "But it worked on my machine". It's fun to test and find bugs. It's fun to check items off in test plans. It's fun to see test automation run and pass. But none of those things matter if your end user has a poor experience with your application.
Saturday, June 6, 2020
Adventures in Node: Promises
Have you ever written an automated UI test that uses Javascript, and when you went to assert on a response, you got Promise {pending} instead of what you were expecting? This really frustrated me when I first encountered it! A developer I was working with explained that this is because Javascript processes commands asynchronously through the use of promises. I sort of understood what he meant, so I tried to work with it as best I could, but I didn't really get it.
As I mentioned in this post, I've been taking a really awesome course on Node.js. It's much more extensive than any programming language course I've ever taken, even the ones I took in college. So I'm starting to understand Node concepts more clearly, and one of those concepts is promises! In this post I'll explain why Javascript and Node need promises and show an example of how they work.

Javascript needs promises because it is a single-threaded language, meaning it can only do one thing at a time. If we had a program where we needed to do three things, such as make an http request, alphabetize a list, and update a record in a database, we wouldn't want to have to wait around for each of those tasks to finish before we went on to the next one, because our program would be very slow! So Javascript is designed to be asynchronous- it can start a task, and then while it's waiting for that task to complete, it can start the next task.
Our program with three things might actually run like this:
start the http request
start alphabetizing the list
start updating the record in the database
finish alphabetizing the list
finish updating the record in the database
finish the http request
The way that Javascript and Node manage this is through the use of promises. Let's take a look at a promise:
const sumChecker = new Promise((resolve, reject) => {
if (a+b==c) {
resolve('You are correct!)
}
else {
reject('Sorry, your math is wrong.')
}
}
This function called sumChecker is a promise. It's going to have two possible results: resolve and reject. If the sum is correct, it resolves the promise, and if it's incorrect, it rejects it. All promises behave in this way; there will be an option to resolve the promise and an option to reject the promise.
When the promise is called, either resolve or reject will be returned; you can't ever return both. Let's look at an example of calling the promise:
sumChecker.then((result) => {
console.log('Success!', result)
}).catch((error) => {
console.log('Error!', error)
})
The result that is returned from calling the promise will either be resolve or reject. If the result is resolve, then the program knows to continue and will return the resolve message. If the result is reject, then the program knows to throw an error and will return the reject message.
You can try this for yourself if you have Node installed! Simply copy the promise and the call and paste them into your favorite code editor. Then at the beginning of the file, add these lines:
var a = 1
var b = 2
var c = 3
Save the file with the name myfile.js, navigate in the command line to the file's location, and run the file with the command node myfile.js. You should see this response: Success! You are correct!
If you make a change to the c variable and set it to 4, save and run the command again, you'll see this response: Error! Sorry, your math is wrong.
Let's put a log statement in between the promise and the call to the promise that looks like this: console.log(sumChecker), so we can see the state of sumChecker before we've called it. If we change the value of c back to 3 so we'll get a positive result, save the file, and run the program with node myfile.js now, we'll get the result Promise { 'You are correct!'} in addition to the response we got earlier. That seems easy! But the reason why we can get the promise resolved so quickly is because the sumChecker promise executes really fast. Let's see what happens if we make the sumChecker work more slowly, like a real promise would.
Update the sumChecker promise to look like this:
const sumChecker = new Promise((resolve, reject) => {
if (a+b==c) {
setTimeout(() => {
resolve('You are correct!)
}, 2000)
}
else {
reject('Sorry, your math is wrong.')
}
}
All we're doing here is adding a two-second timeout to the resolved promise. Save the file, and run the program again with node myfile.js. This time you'll first get the result Promise { <pending> }, and after two seconds, you'll get the result Success! You are correct!
Now it should be clear why you get Promise { <pending> } when you are making Javascript or Node calls. It's because the promise hasn't completed yet. This is why we use the .then() command. We wait for the response to the call to come back, then we do something with the response. If we're writing a test, at that point we can assert on our result.
I hope you'll take the time to try running this file with Node, because there's nothing quite like doing hands-on work to generate understanding. You can try changing the variables or any of the response messages to get a feel for how it's working. Here's the final version of the file if you'd like to copy and paste it:
var a = 1
var b = 2
var c = 3
const sumChecker = new Promise((resolve, reject) => {
if (a+b==c) {
setTimeout(() => {
resolve('You are correct!')
}, 2000)
}
else {
reject('Sorry, your math is wrong.')
}
})
console.log(sumChecker)
sumChecker.then((result) => {
console.log('Success!', result)
}).catch((error) => {
console.log('Error!', error)
})
Enjoy your new-found understanding of promises!
As I mentioned in this post, I've been taking a really awesome course on Node.js. It's much more extensive than any programming language course I've ever taken, even the ones I took in college. So I'm starting to understand Node concepts more clearly, and one of those concepts is promises! In this post I'll explain why Javascript and Node need promises and show an example of how they work.

Javascript needs promises because it is a single-threaded language, meaning it can only do one thing at a time. If we had a program where we needed to do three things, such as make an http request, alphabetize a list, and update a record in a database, we wouldn't want to have to wait around for each of those tasks to finish before we went on to the next one, because our program would be very slow! So Javascript is designed to be asynchronous- it can start a task, and then while it's waiting for that task to complete, it can start the next task.
Our program with three things might actually run like this:
start the http request
start alphabetizing the list
start updating the record in the database
finish alphabetizing the list
finish updating the record in the database
finish the http request
The way that Javascript and Node manage this is through the use of promises. Let's take a look at a promise:
const sumChecker = new Promise((resolve, reject) => {
if (a+b==c) {
resolve('You are correct!)
}
else {
reject('Sorry, your math is wrong.')
}
}
This function called sumChecker is a promise. It's going to have two possible results: resolve and reject. If the sum is correct, it resolves the promise, and if it's incorrect, it rejects it. All promises behave in this way; there will be an option to resolve the promise and an option to reject the promise.
When the promise is called, either resolve or reject will be returned; you can't ever return both. Let's look at an example of calling the promise:
sumChecker.then((result) => {
console.log('Success!', result)
}).catch((error) => {
console.log('Error!', error)
})
The result that is returned from calling the promise will either be resolve or reject. If the result is resolve, then the program knows to continue and will return the resolve message. If the result is reject, then the program knows to throw an error and will return the reject message.
You can try this for yourself if you have Node installed! Simply copy the promise and the call and paste them into your favorite code editor. Then at the beginning of the file, add these lines:
var a = 1
var b = 2
var c = 3
Save the file with the name myfile.js, navigate in the command line to the file's location, and run the file with the command node myfile.js. You should see this response: Success! You are correct!
If you make a change to the c variable and set it to 4, save and run the command again, you'll see this response: Error! Sorry, your math is wrong.
Let's put a log statement in between the promise and the call to the promise that looks like this: console.log(sumChecker), so we can see the state of sumChecker before we've called it. If we change the value of c back to 3 so we'll get a positive result, save the file, and run the program with node myfile.js now, we'll get the result Promise { 'You are correct!'} in addition to the response we got earlier. That seems easy! But the reason why we can get the promise resolved so quickly is because the sumChecker promise executes really fast. Let's see what happens if we make the sumChecker work more slowly, like a real promise would.
Update the sumChecker promise to look like this:
const sumChecker = new Promise((resolve, reject) => {
if (a+b==c) {
setTimeout(() => {
resolve('You are correct!)
}, 2000)
}
else {
reject('Sorry, your math is wrong.')
}
}
All we're doing here is adding a two-second timeout to the resolved promise. Save the file, and run the program again with node myfile.js. This time you'll first get the result Promise { <pending> }, and after two seconds, you'll get the result Success! You are correct!
Now it should be clear why you get Promise { <pending> } when you are making Javascript or Node calls. It's because the promise hasn't completed yet. This is why we use the .then() command. We wait for the response to the call to come back, then we do something with the response. If we're writing a test, at that point we can assert on our result.
I hope you'll take the time to try running this file with Node, because there's nothing quite like doing hands-on work to generate understanding. You can try changing the variables or any of the response messages to get a feel for how it's working. Here's the final version of the file if you'd like to copy and paste it:
var a = 1
var b = 2
var c = 3
const sumChecker = new Promise((resolve, reject) => {
if (a+b==c) {
setTimeout(() => {
resolve('You are correct!')
}, 2000)
}
else {
reject('Sorry, your math is wrong.')
}
})
console.log(sumChecker)
sumChecker.then((result) => {
console.log('Success!', result)
}).catch((error) => {
console.log('Error!', error)
})
Saturday, May 30, 2020
Book Review: Perfect Software and Other Illusions About Testing
"Perfect Software and Other Illusions About Testing", by Gerald Weinberg, is the best book on testing I have ever read. It is a must-read for anyone who works with software: CEOs, CTOs, scrum masters, team leads, developers, product owners, business analysts, and software testers.
Before I get into why this book is so great, I'll first acquaint you with the author. Gerald "Jerry" Weinberg (1933-2018) was involved in the creation of software for over fifty years. Early in his career he worked for NASA on Project Mercury, the project that created spacecraft that allowed a human to orbit the earth. For decades he consulted with companies about building quality software, and over those years he gained a great deal of wisdom about software testing. "Perfect Software", which was published in 2014, seems to me to be the culmination of his years of experience.

The book is divided into several chapters, each of which looks at a particular aspect of software testing. Many examples are given from Jerry's consulting experience, and each chapter closes with a summary and a list of common mistakes that companies make. Rather than summarizing the lessons he imparts, I think it would be best to include Jerry's own words here. Here are some of my favorite quotes from the book:
"Before you even begin to test, ask yourself: What questions do I have about this product's risks? Will testing help answer these questions?"
"There are an infinite number of possible tests...Since we can't test everything, any set of real tests is some kind of sample- a portion, piece, or segment that is in some way representative of a whole set of possible tests."
"Knowing about the structure of the software you're testing can help you to identify special cases, subtle features, and important ranges to try- all of which can help narrow the inference gap between what the software can do and what it will do during actual use."
"Testing gathers information about a product; it does not fix things it finds that are wrong."
"If you're going to ignore information or go ahead with predetermined plans despite what the tests turn up, don't bother testing."
"If you blame messengers for bringing news you don't want to hear, you'll be rewarded by not hearing the news you should hear."
"Quality is a product of the entire development process. Poor testing can lead to poor quality, but good testing won't lead to good quality unless all other parts of the process are in place and performed properly."
"Testing starts at project conception, or before. If you don't know this, you don't understand testing at all."
"Without a process that includes regular technical reviews, no project will rise above mediocrity, no matter how good its machine-testing process."
"No developer is good enough to consistently do it alone, and do it right."
"Data are meaningless until someone determines their meaning. Different people give different meanings to the same data. Gather data, then sit down and ponder at least three possible meanings."
"When someone says, 'The response should be very fast', what does that mean, exactly? What meanings do 'should', 'very', and 'fast' give to the stated information?"
"Numbers can be useful, but only if they're validated by personal observation and set in context by a story about them."
"Garbage arranged in a spreadsheet is still garbage."
Jerry uses many great hypothetical scenarios to illustrate his points, and he also uses real-world examples from his years of consulting. Here are some of my favorites:
If you would like to think about what role testing plays in your software development project, what constitutes a good test, how to plan testing for a project, or how to interpret test data in order to make management decisions, then "Perfect Software" is the book for you. I plan to re-read this book every year to make sure that I have fully retained all the lessons it offers.
Before I get into why this book is so great, I'll first acquaint you with the author. Gerald "Jerry" Weinberg (1933-2018) was involved in the creation of software for over fifty years. Early in his career he worked for NASA on Project Mercury, the project that created spacecraft that allowed a human to orbit the earth. For decades he consulted with companies about building quality software, and over those years he gained a great deal of wisdom about software testing. "Perfect Software", which was published in 2014, seems to me to be the culmination of his years of experience.

The book is divided into several chapters, each of which looks at a particular aspect of software testing. Many examples are given from Jerry's consulting experience, and each chapter closes with a summary and a list of common mistakes that companies make. Rather than summarizing the lessons he imparts, I think it would be best to include Jerry's own words here. Here are some of my favorite quotes from the book:
"Before you even begin to test, ask yourself: What questions do I have about this product's risks? Will testing help answer these questions?"
"There are an infinite number of possible tests...Since we can't test everything, any set of real tests is some kind of sample- a portion, piece, or segment that is in some way representative of a whole set of possible tests."
"Knowing about the structure of the software you're testing can help you to identify special cases, subtle features, and important ranges to try- all of which can help narrow the inference gap between what the software can do and what it will do during actual use."
"Testing gathers information about a product; it does not fix things it finds that are wrong."
"If you're going to ignore information or go ahead with predetermined plans despite what the tests turn up, don't bother testing."
"If you blame messengers for bringing news you don't want to hear, you'll be rewarded by not hearing the news you should hear."
"Quality is a product of the entire development process. Poor testing can lead to poor quality, but good testing won't lead to good quality unless all other parts of the process are in place and performed properly."
"Testing starts at project conception, or before. If you don't know this, you don't understand testing at all."
"Without a process that includes regular technical reviews, no project will rise above mediocrity, no matter how good its machine-testing process."
"No developer is good enough to consistently do it alone, and do it right."
"Data are meaningless until someone determines their meaning. Different people give different meanings to the same data. Gather data, then sit down and ponder at least three possible meanings."
"When someone says, 'The response should be very fast', what does that mean, exactly? What meanings do 'should', 'very', and 'fast' give to the stated information?"
"Numbers can be useful, but only if they're validated by personal observation and set in context by a story about them."
"Garbage arranged in a spreadsheet is still garbage."
Jerry uses many great hypothetical scenarios to illustrate his points, and he also uses real-world examples from his years of consulting. Here are some of my favorites:
- The tester who didn't log a bug he found because it wasn't in "his" component
- The manager who thought that the project was ready to ship because they ran 600,000 test cases and "nothing crashed the system"
- The team who thought their biggest problem was their bug-tracking system, because the system couldn't handle their 140,000 open bugs
- The team who took so long to triage bugs that couldn't make a decision on any of them, resulting in 129 undiscussed and unfixed bugs
- The tester who assumed that her new automated test tool was working correctly because all the tests displayed in green at the end
- The developer-tester team who were gaming the bug bounty system by having the developer add bugs to the code, the tester find the bugs quickly, and the developer fix them just as quickly, resulting in rewards for both
- The VP of Development who wanted a really big written test plan so he could have something big to slam down on a desk to "prove" that they had tested well
If you would like to think about what role testing plays in your software development project, what constitutes a good test, how to plan testing for a project, or how to interpret test data in order to make management decisions, then "Perfect Software" is the book for you. I plan to re-read this book every year to make sure that I have fully retained all the lessons it offers.
Saturday, May 23, 2020
Rarely Used HTTP Methods
A couple of months ago, one of the developers I work with asked me to test a bug fix he'd done. In order to test it, I'd need to make an HTTP request with the OPTIONS method. I'd never heard of the OPTIONS method, and it got me thinking: what other HTTP methods did I not know about? In this post, I'll talk about four rarely used methods and and how you might use them in your testing.
 OPTIONS:
OPTIONS:
This method returns whatever methods are allowed for a particular endpoint. For example, if you had a URL called http://cats.com/cat, and you could use it to get a list of cats or add a cat, the methods that the OPTIONS request would return would be GET and POST.
OPTIONS demo:
Let's use the Restful-Booker API to try out the OPTIONS method. Assuming you have Postman installed, we'll create a new GET request that calls this URL: https://restful-booker.herokuapp.com/booking. When you run this request, you'll see a list of all the available hotel-bookings for the app in the response body. Now let's change the method from GET to OPTIONS. When you run this request, you'll see GET, HEAD, and POST in the response body. These are the three methods that are available for this endpoint.
Why would you use the OPTIONS method?
If you are testing an API, this is a great way to find out if there are any valid endpoints that you don't know about. This can reveal more features for you to test, or it could potentially reveal a security hole. For example, maybe your API shouldn't really have a DELETE method, but someone implemented it by mistake.
HEAD:
This method returns only the headers of the response to a GET request. It's used if you want to check the response headers without putting pressure on the server to return other data.
HEAD demo:
We'll use the very same URL that we used for our OPTIONS demo. First, let's return our method to GET. Run the request, and see that you get a response body with the list of available bookings. Take a look at the headers that were returned with the response: Server, Connection, X-Powered-By, Content-Type, Content-Length, Etag, Date, and Via. Now let's change our verb to HEAD and re-run the request. We won't get anything in the body of the response, but we will get those same eight headers.
Why would you use the HEAD method?
This method would be a great way to check the headers of a GET response without having to actually return data. Headers are important because they often help to enforce security rules. If you know what headers your API should be returning, you can run this request on all of your endpoints to make sure that the right headers are being used.
CONNECT:
This method establishes a tunnel to the server that is identified by a URL. It's often used for proxy connections.
CONNECT demo:
For this demo, you'll need to have curl enabled. You can check to see if curl is installed on your machine by typing curl --version in your command line window. If you get a version back, you have curl installed.
To try out CONNECT, type this command into your command line window: curl -v CONNECT http:///kristinjackvony.com. Take a look at the response you get; about nine lines from the bottom, you'll see the message "301 Moved Permanently". This is because I recently changed this domain name to point to my Thinking Tester webpage instead of my personal webpage. I didn't do that because of this tutorial, but it wound up being useful!
Why would you use CONNECT?
You'd use CONNECT any time you want to see exactly what happens when you try connecting to an HTTP resource. This could be helpful with security testing, and any time you are using a proxy.
TRACE:
This method is similar to CONNECT in that it connects to a resource, but it also tries to get a response back.
TRACE demo:
We'll use curl again to try out TRACE. Type this command in the command window: curl -v TRACE http://isithalloween.com. You'll get back some response headers, plus the source code for the page.
Why would you use TRACE?
This would be good for security testing. Because you get the source code for the page in the response, you can inspect it to see if there are any cookies or authentication headers that a malicious user could exploit.
I hope you've gotten some good testing ideas from these rarely used HTTP methods! In my research I found all kinds of other methods that appear to no longer be in use, such as COPY, LINK, UNLINK, LOCK, and UNLOCK. Have you ever used these, or other rare methods? Tell me about it in the comments!

This method returns whatever methods are allowed for a particular endpoint. For example, if you had a URL called http://cats.com/cat, and you could use it to get a list of cats or add a cat, the methods that the OPTIONS request would return would be GET and POST.
OPTIONS demo:
Let's use the Restful-Booker API to try out the OPTIONS method. Assuming you have Postman installed, we'll create a new GET request that calls this URL: https://restful-booker.herokuapp.com/booking. When you run this request, you'll see a list of all the available hotel-bookings for the app in the response body. Now let's change the method from GET to OPTIONS. When you run this request, you'll see GET, HEAD, and POST in the response body. These are the three methods that are available for this endpoint.
Why would you use the OPTIONS method?
If you are testing an API, this is a great way to find out if there are any valid endpoints that you don't know about. This can reveal more features for you to test, or it could potentially reveal a security hole. For example, maybe your API shouldn't really have a DELETE method, but someone implemented it by mistake.
HEAD:
This method returns only the headers of the response to a GET request. It's used if you want to check the response headers without putting pressure on the server to return other data.
HEAD demo:
We'll use the very same URL that we used for our OPTIONS demo. First, let's return our method to GET. Run the request, and see that you get a response body with the list of available bookings. Take a look at the headers that were returned with the response: Server, Connection, X-Powered-By, Content-Type, Content-Length, Etag, Date, and Via. Now let's change our verb to HEAD and re-run the request. We won't get anything in the body of the response, but we will get those same eight headers.
Why would you use the HEAD method?
This method would be a great way to check the headers of a GET response without having to actually return data. Headers are important because they often help to enforce security rules. If you know what headers your API should be returning, you can run this request on all of your endpoints to make sure that the right headers are being used.
CONNECT:
This method establishes a tunnel to the server that is identified by a URL. It's often used for proxy connections.
CONNECT demo:
For this demo, you'll need to have curl enabled. You can check to see if curl is installed on your machine by typing curl --version in your command line window. If you get a version back, you have curl installed.
To try out CONNECT, type this command into your command line window: curl -v CONNECT http:///kristinjackvony.com. Take a look at the response you get; about nine lines from the bottom, you'll see the message "301 Moved Permanently". This is because I recently changed this domain name to point to my Thinking Tester webpage instead of my personal webpage. I didn't do that because of this tutorial, but it wound up being useful!
Why would you use CONNECT?
You'd use CONNECT any time you want to see exactly what happens when you try connecting to an HTTP resource. This could be helpful with security testing, and any time you are using a proxy.
TRACE:
This method is similar to CONNECT in that it connects to a resource, but it also tries to get a response back.
TRACE demo:
We'll use curl again to try out TRACE. Type this command in the command window: curl -v TRACE http://isithalloween.com. You'll get back some response headers, plus the source code for the page.
Why would you use TRACE?
This would be good for security testing. Because you get the source code for the page in the response, you can inspect it to see if there are any cookies or authentication headers that a malicious user could exploit.
I hope you've gotten some good testing ideas from these rarely used HTTP methods! In my research I found all kinds of other methods that appear to no longer be in use, such as COPY, LINK, UNLINK, LOCK, and UNLOCK. Have you ever used these, or other rare methods? Tell me about it in the comments!
Saturday, May 16, 2020
Seven Steps to Solve Any Coding Problem
I am not the world's greatest coder, although I am getting better every year. One thing that I'm really improving on is my ability to solve coding problems. I'm not talking about those coding challenges that you can get online or in a job interview; I'm talking about those real-world problems, like "How are we going to create an automated test for this?" Here are the seven steps I use to solve any coding problem.

Step One: Remember what problem you are trying to solve
When you're trying to figure out how to do something, it can be easy to forget what your original intent was. For example, let's say you are trying to access a specific element on a web page, and you're having a really tough time doing so; perhaps the element is in a popup that you can't reach, or it's blocked by something else. It's easy to get so bogged down in trying to solve this problem that you lose sight of what your original intent was- to add a new user to the system. When you remember this, you realize that you could actually add a new user to the system by calling the database directly, avoiding the whole issue that you were stuck on!
Step Two: Set Small Steps
I often have what I want to do in my code all figured out long before I know how I'm going to it. And I used to just write a whole bunch of code even if I wasn't sure it was all going to work correctly. Then when I tried to run the code, it didn't work; but I wrote so much code that I didn't know whether I had one problem or many. This is why I now set small steps when I code. For example, when I was trying to write the email test that I mentioned in last week's post, I first set myself the goal of just reaching the Gmail API. I didn't care what kind of token I used, or what information I got back; I just wanted a response. Once I had solved that, then I worked on trying to get the specific response that I wanted. This strategy also keeps me from getting frustrated or overwhelmed.
Step Three: Change One Thing at a Time
This step is similar to Step Two, but it's good for those times when your code isn't working. It's very tempting to thrash around and try a number of different solutions, sometimes all at once, but that's not very helpful. Even if you get your code to work by this method, you won't know which change it was that caused the code to work, therefore you don't know which changes were superfluous. It's much better to make one small change, see if it works, remove that change and try a different change, and so on. Not only will you solve your problem faster this way, but you'll be learning as you go, and what you learn will be very valuable for the next time you have a problem.
Step Four: Save All Your Work
I learned this one the hard way when I was first writing UI automation. I had absolutely no idea what I was doing, and sometimes I'd try something that didn't completely work and then delete it and try something else. Then I'd realize that I needed some of the lines of code from the first thing I tried, but I had deleted them, so I had to start from scratch to find them again. Now when I'm solving a new coding challenge I create a document that I call my scratch pad, and when I remove anything from my code I copy it and paste it in the scratch pad, just in case I'll need it again. This has helped me solve challenges much more efficiently.
Step Five: See What Others Have Done
People who are good at solving coding problems are usually also masters of Google Fu: the art of knowing the right Google search to use to get them the answers they need. When I first started writing test automation, I was not very good at Google Fu, because I often wasn't sure of what to call the thing I wanted to do. As I've grown in experience, I've become better at knowing the terminology of whatever language I'm using, so if I've forgotten something like whether I should be using a static method I can structure my search so I can quickly find the right answer. The answers you find on the Internet are not always the right ones, and sometimes they aren't even good ones, but they often provide clues that can help you solve your problem.
Step Six: Level Up Your Skills
As I mentioned in this post, I've been taking a really great Node.js course over the last three months. I'm not even halfway done with it yet, and I've already learned so much about Node that I didn't understand before. Now that I understand more, writing code in Node.js is so much easier. Rather than just copying and pasting examples from someone on Stack Overflow, I can make good decisions about how to set things up, and when I understand what's going on, I can write code so much faster. Take some time to really learn a coding language; it's an investment that will be worth it!
Step Seven: Ask For Help
If you've finished all your other steps and still haven't solved your problem, it's time to ask for help. This should definitely not be Step One in your process. Running for help every time something gets hard will not make you a better coder. Imagine for a while that there's no one who can help you, and see how far you can get on your own. See what kind of lessons you can learn from the process. Then if you do need to ask for help, you'll be able to accurately describe the problem in such a way that your helper will probably be able to give you some answers very quickly. You'll save them time, which they will appreciate.
Coding is not magic: while there are all sorts of complex and weird things out there in the world of software, an answer exists for every question. By using these seven steps, you'll take some of the mystery out of coding and become a better thinker in the process!

Step One: Remember what problem you are trying to solve
When you're trying to figure out how to do something, it can be easy to forget what your original intent was. For example, let's say you are trying to access a specific element on a web page, and you're having a really tough time doing so; perhaps the element is in a popup that you can't reach, or it's blocked by something else. It's easy to get so bogged down in trying to solve this problem that you lose sight of what your original intent was- to add a new user to the system. When you remember this, you realize that you could actually add a new user to the system by calling the database directly, avoiding the whole issue that you were stuck on!
Step Two: Set Small Steps
I often have what I want to do in my code all figured out long before I know how I'm going to it. And I used to just write a whole bunch of code even if I wasn't sure it was all going to work correctly. Then when I tried to run the code, it didn't work; but I wrote so much code that I didn't know whether I had one problem or many. This is why I now set small steps when I code. For example, when I was trying to write the email test that I mentioned in last week's post, I first set myself the goal of just reaching the Gmail API. I didn't care what kind of token I used, or what information I got back; I just wanted a response. Once I had solved that, then I worked on trying to get the specific response that I wanted. This strategy also keeps me from getting frustrated or overwhelmed.
Step Three: Change One Thing at a Time
This step is similar to Step Two, but it's good for those times when your code isn't working. It's very tempting to thrash around and try a number of different solutions, sometimes all at once, but that's not very helpful. Even if you get your code to work by this method, you won't know which change it was that caused the code to work, therefore you don't know which changes were superfluous. It's much better to make one small change, see if it works, remove that change and try a different change, and so on. Not only will you solve your problem faster this way, but you'll be learning as you go, and what you learn will be very valuable for the next time you have a problem.
Step Four: Save All Your Work
I learned this one the hard way when I was first writing UI automation. I had absolutely no idea what I was doing, and sometimes I'd try something that didn't completely work and then delete it and try something else. Then I'd realize that I needed some of the lines of code from the first thing I tried, but I had deleted them, so I had to start from scratch to find them again. Now when I'm solving a new coding challenge I create a document that I call my scratch pad, and when I remove anything from my code I copy it and paste it in the scratch pad, just in case I'll need it again. This has helped me solve challenges much more efficiently.
Step Five: See What Others Have Done
People who are good at solving coding problems are usually also masters of Google Fu: the art of knowing the right Google search to use to get them the answers they need. When I first started writing test automation, I was not very good at Google Fu, because I often wasn't sure of what to call the thing I wanted to do. As I've grown in experience, I've become better at knowing the terminology of whatever language I'm using, so if I've forgotten something like whether I should be using a static method I can structure my search so I can quickly find the right answer. The answers you find on the Internet are not always the right ones, and sometimes they aren't even good ones, but they often provide clues that can help you solve your problem.
Step Six: Level Up Your Skills
As I mentioned in this post, I've been taking a really great Node.js course over the last three months. I'm not even halfway done with it yet, and I've already learned so much about Node that I didn't understand before. Now that I understand more, writing code in Node.js is so much easier. Rather than just copying and pasting examples from someone on Stack Overflow, I can make good decisions about how to set things up, and when I understand what's going on, I can write code so much faster. Take some time to really learn a coding language; it's an investment that will be worth it!
Step Seven: Ask For Help
If you've finished all your other steps and still haven't solved your problem, it's time to ask for help. This should definitely not be Step One in your process. Running for help every time something gets hard will not make you a better coder. Imagine for a while that there's no one who can help you, and see how far you can get on your own. See what kind of lessons you can learn from the process. Then if you do need to ask for help, you'll be able to accurately describe the problem in such a way that your helper will probably be able to give you some answers very quickly. You'll save them time, which they will appreciate.
Coding is not magic: while there are all sorts of complex and weird things out there in the world of software, an answer exists for every question. By using these seven steps, you'll take some of the mystery out of coding and become a better thinker in the process!
Saturday, May 9, 2020
Testing Email Without Tears
Several years ago, when I was first learning test automation, I needed to create a test for my company's email service. I had configured the service to deliver an email every day, and I wanted an automated test that would check my test Gmail account and determine if the email had been delivered. At the time, the only automated testing I knew about was Selenium Webdriver with Java. So I wrote an automated test that would open a browser, navigate to the Gmail client, log in, and search the page for the email.
This test didn't work out very well. First of all, there could be a delay of up to ten minutes before the email was delivered, so it wound up being a long-running test. Secondly, any time Google made changes to the email page, I had to update my element locators. And finally, I didn't have a good way to identify the email, so sometimes the test would think that yesterday's email was today's and mistakenly pass the test.
So when I recently found myself with the need to test an email delivery again, I knew there had to be a better way! This time I created an automated test using the Gmail API, and I'll share here how I did it.

The first step is obviously to obtain a Gmail account to test with. You will not want this to be your personal Gmail account! I already had a test account that is shared with a number of other testers at my company.
The trickiest part of using the Gmail API is coming up with an access token to use for the API requests. Using this post by Martin Fowler, this blog post, this Quickstart documentation from Google, and some trial and error, I was able to obtain a refresh token that could be used to request the access token. The Gmail API Quickstart application is easy to create, and can be done in a number of different languages, such as .NET, Java, NodeJS, Python, and Ruby. You just choose which language you want to use and follow the simple steps.
Once the Quickstart application has been created, you run it. When the application runs, it will prompt you to authenticate your Gmail account and give permission for the Gmail API to access the account. After this is completed, you'll have a token.json file that contains a refresh token and a credentials.json file that contains a client id, a client secret, and a redirect URI.
I ran the Quickstart application in .NET, but I didn't actually want my test to be in .NET. I wanted to write my test in Powershell. For those unfamiliar with Powershell, it's a Windows command line language that offers more advanced commands than the traditional command line. I took the refresh token, client id, client secret, and redirect URI from the Quickstart application files and created this request body:
Then I used this request to create a refreshed token:
$RefreshedToken = Invoke-WebRequest -Uri "https://accounts.google.com/o/oauth2/token" `
-Method POST -Body $RefreshTokenParams | ConvertFrom-Json
The refreshed token contained the access token I needed, so I grabbed it like this:
$AccessToken = $RefreshedToken.access_token
Now I had the token I needed to make requests from the Gmail API. Note that the refresh token I got from the Gmail Quickstart application won't last forever; in the event that it gets revoked at some point in the future, I can simply run the Quickstart application again and I'll have a new token to use in my script.
Next, I added a command in my script to send an email. I can do this with a simple POST request using my team's email function; how you create an email for testing will of course vary.
Then I created the request to the Gmail API:
This test didn't work out very well. First of all, there could be a delay of up to ten minutes before the email was delivered, so it wound up being a long-running test. Secondly, any time Google made changes to the email page, I had to update my element locators. And finally, I didn't have a good way to identify the email, so sometimes the test would think that yesterday's email was today's and mistakenly pass the test.
So when I recently found myself with the need to test an email delivery again, I knew there had to be a better way! This time I created an automated test using the Gmail API, and I'll share here how I did it.

The first step is obviously to obtain a Gmail account to test with. You will not want this to be your personal Gmail account! I already had a test account that is shared with a number of other testers at my company.
The trickiest part of using the Gmail API is coming up with an access token to use for the API requests. Using this post by Martin Fowler, this blog post, this Quickstart documentation from Google, and some trial and error, I was able to obtain a refresh token that could be used to request the access token. The Gmail API Quickstart application is easy to create, and can be done in a number of different languages, such as .NET, Java, NodeJS, Python, and Ruby. You just choose which language you want to use and follow the simple steps.
Once the Quickstart application has been created, you run it. When the application runs, it will prompt you to authenticate your Gmail account and give permission for the Gmail API to access the account. After this is completed, you'll have a token.json file that contains a refresh token and a credentials.json file that contains a client id, a client secret, and a redirect URI.
I ran the Quickstart application in .NET, but I didn't actually want my test to be in .NET. I wanted to write my test in Powershell. For those unfamiliar with Powershell, it's a Windows command line language that offers more advanced commands than the traditional command line. I took the refresh token, client id, client secret, and redirect URI from the Quickstart application files and created this request body:
$RefreshTokenParams = @{
client_id=$clientId;
client_secret=$secret;
refresh_token=$refreshToken;
grant_type='refresh_token';
}
Then I used this request to create a refreshed token:
$RefreshedToken = Invoke-WebRequest -Uri "https://accounts.google.com/o/oauth2/token" `
-Method POST -Body $RefreshTokenParams | ConvertFrom-Json
The refreshed token contained the access token I needed, so I grabbed it like this:
$AccessToken = $RefreshedToken.access_token
Now I had the token I needed to make requests from the Gmail API. Note that the refresh token I got from the Gmail Quickstart application won't last forever; in the event that it gets revoked at some point in the future, I can simply run the Quickstart application again and I'll have a new token to use in my script.
Next, I added a command in my script to send an email. I can do this with a simple POST request using my team's email function; how you create an email for testing will of course vary.
Then I created the request to the Gmail API:
$header = @{
Authorization = "Bearer $AccessToken"
}
$emailList = Invoke-RestMethod `
-Uri 'https://www.googleapis.com/gmail/v1/users/<emailaddresshere>/messages' `
-Method 'GET' -Header $header
The <emailaddresshere> was of course replaced by my test email address.
This request got me a list of the twenty-five most recent emails to my test account. I grabbed just the first ten of them, then I looped through those ten to find the email that matched the one I sent.
You may be wondering at this point how I was able to tell my latest email apart from all the other emails. I did this by creating a random GUID and including that GUID at the very beginning of the email message. The Gmail client saves the first several characters of an email message as a "snippet", and as I looped through the ten emails I saved, I looked for the GUID in each snippet. When I found a match, I was able to programmatically examine that email to see if it had the attachment I was expecting.
Of course, emails are not delivered instantaneously, even when we're checking the API rather than logging into the client on the browser. So I built in some waits and retries to make sure that my test didn't fail simply because the email hadn't been delivered yet. So far, waiting thirty seconds has been enough to ensure that the email has been delivered, meaning my test takes well under a minute; much faster than that UI test I created years ago!
The moral of this story is not just that testing email is easier and more reliable with an API test than a UI test; it's also that APIs are great to test all kinds of things! The next time you find yourself needing to access a third-party application for an automated test, see if that app has an API. Your test will be less flaky, so you won't have to waste lots of time rerunning and debugging it!
Saturday, May 2, 2020
Six Testing Personas to Avoid
If you are working for a company that makes software for end users, you have probably heard of user personas. A user persona is a representation of one segment of your application's end users. For example, if you worked for a company that made a website for home improvement supplies, one of your user personas might be New Homeowner Nick, who has just purchased his first home and might not have much experience fixing small things in his house. Another persona might be Do-It-Yourself Dora, who has lots of experience fixing everything in her home herself.

It occurred to me recently that there are also testing personas. But unlike our user personas, these personas are ones we want to avoid! Read on to see if one of these personas applies to you.
1. Test Script Ted
Ted loves running manual test scripts and checking them off when they're completed. It gives him a feeling of satisfaction to see tests pass. He doesn't particularly care if he doesn't understand how his application works; he's just satisfied to do what he's told. But because he doesn't understand how the application works, he sometimes misses important bugs. If he sees something strange, but it's not addressed in the test plan, he just lets it slide. His job is to test, not figure things out!
2. Automation Annie
Annie considers herself an automation engineer. She considers manual testing a colossal waste of her time. She'd rather get into the hard stuff: creating and maintaining automated tests! When a new feature is created, she doesn't bother to do any exploratory testing; she'll just start coding and she figures her great automation will uncover any issues.
What Ted and Annie have in common:
Ted and Annie are making the same mistake for different reasons; they are not taking the time to really learn how their application works. They're both missing bugs because of a lack of understanding; Ted doesn't understand the code that makes the features work, and Annie doesn't understand the use cases of the application.
How not to be Ted or Annie:
To be a thorough tester, it's important to take the time to understand how your features work. Try them out manually; explore their limits. Look in the code to see if there are other ways you might test them. Ask questions when you see things that don't make sense.
3. Process Patty
Patty is passionate about quality. She likes things to work correctly. But she likes having processes and standards even more! She's got test plans and matrices she's expecting her team to follow to the letter. Regression testing must be completed before any exploratory testing is done, and there are hundreds of regression tests to be run. The trouble is, with releases happening every two weeks there's no time to do any exploratory testing. There's no time to stop and think about new ways to test the product, or what might be missing. The team needs to get all those regression tests completed!
4. Rabbit Hole Ray
Ray is passionate about quality too; he doesn't want any bug to go unnoticed. So when he sees something strange in the application when it runs on IE10, he's determined to find out what's wrong! He will take days to investigate, looking at logs and trying different configuration scenarios to reproduce it. He doesn't want to be bothered with the standard regression tests that he's leaving undone as the feature is being released. And he doesn't care that only 1% of their customers are using IE10. He's going to solve the mystery!
What Patty and Ray have in common:
Patty and Ray are both wasting time. They are focused on something other than the primary objective: releasing good software on time with a minimum of defects. Patty is so caught up in the process that she doesn't see the importance of exploratory testing, which could find new bugs. And Ray is so obsessed with that elusive bug he's exploring that he's ignoring important testing that would impact many more users.
How not to be Patty or Ray:
When testing a new feature or regression testing existing ones, it's important to think about which tests will have the biggest impact and plan your testing accordingly. Be careful not to get too caught up in processes, and if that elusive bug you're searching for won't be that impactful to end users, let it go.
5. Job Security Jim:
Jim's been working at his current position for years. He knows the application like the back of his hand. He's the go-to guy for all those questions about how the most ancient features behave. He knows there's no way the company will let him go; he knows too much! So he doesn't feel like there's any reason to learn new skills. What he knows has served him just fine so far. Who needs to waste time after work learning the latest programming language or the newest testing tool?
6. Conference Connie:
Connie is so excited about tech! She loves to hear about the latest testing techniques and the latest development trends. She signs up for webinars, goes to conferences, reads blog posts, and takes courses online. She knows a little about just about everything! But she's never actually implemented any of the new things she learns. She's so busy going to conferences and webinars that she barely has time to do her regular testing tasks. And besides, trying things out is a lot of work. It's easier to just see how other people have done it.
What Jim and Connie have in common:
Jim and Connie seem like total opposites at first: Jim doesn't want to learn anything new, and Connie wants to learn everything new. But they actually have the same problem: they are not growing as testers. Jim is content to do everything he's already learned, and doesn't see any reason to learn anything more. But he could be in for a shock one day if his company decides to rewrite the software and he suddenly needs a new skill. And Connie has lots of great ideas, but great ideas don't mean anything unless you actually try them out. Her company isn't benefiting from her knowledge because she's not putting it to use.
How not to be Jim or Connie:
It's important to keep your testing skills fresh by learning new languages, tools, and techniques. You don't have to learn everything under the sun; just pick the things that you think would be most beneficial to your current company, learn them, and then try to implement them in one or two areas. Your teammates will be thankful for the new solutions you introduce, and you'll be developing marketable skills for your next position.
Be a great tester, not a persona!
We all become some of these personas now and then. But if we can be aware of them, we can catch ourselves if we start to slip into Automation Annie or Rabbit Hole Ray, or any of the others. Great testers learn their application better than anyone else, they make good choices about what to test and when, and they keep their skills updated so their testing keeps getting better.
2. Automation Annie
Annie considers herself an automation engineer. She considers manual testing a colossal waste of her time. She'd rather get into the hard stuff: creating and maintaining automated tests! When a new feature is created, she doesn't bother to do any exploratory testing; she'll just start coding and she figures her great automation will uncover any issues.
What Ted and Annie have in common:
Ted and Annie are making the same mistake for different reasons; they are not taking the time to really learn how their application works. They're both missing bugs because of a lack of understanding; Ted doesn't understand the code that makes the features work, and Annie doesn't understand the use cases of the application.
How not to be Ted or Annie:
To be a thorough tester, it's important to take the time to understand how your features work. Try them out manually; explore their limits. Look in the code to see if there are other ways you might test them. Ask questions when you see things that don't make sense.
3. Process Patty
Patty is passionate about quality. She likes things to work correctly. But she likes having processes and standards even more! She's got test plans and matrices she's expecting her team to follow to the letter. Regression testing must be completed before any exploratory testing is done, and there are hundreds of regression tests to be run. The trouble is, with releases happening every two weeks there's no time to do any exploratory testing. There's no time to stop and think about new ways to test the product, or what might be missing. The team needs to get all those regression tests completed!
4. Rabbit Hole Ray
Ray is passionate about quality too; he doesn't want any bug to go unnoticed. So when he sees something strange in the application when it runs on IE10, he's determined to find out what's wrong! He will take days to investigate, looking at logs and trying different configuration scenarios to reproduce it. He doesn't want to be bothered with the standard regression tests that he's leaving undone as the feature is being released. And he doesn't care that only 1% of their customers are using IE10. He's going to solve the mystery!
What Patty and Ray have in common:
Patty and Ray are both wasting time. They are focused on something other than the primary objective: releasing good software on time with a minimum of defects. Patty is so caught up in the process that she doesn't see the importance of exploratory testing, which could find new bugs. And Ray is so obsessed with that elusive bug he's exploring that he's ignoring important testing that would impact many more users.
How not to be Patty or Ray:
When testing a new feature or regression testing existing ones, it's important to think about which tests will have the biggest impact and plan your testing accordingly. Be careful not to get too caught up in processes, and if that elusive bug you're searching for won't be that impactful to end users, let it go.
5. Job Security Jim:
Jim's been working at his current position for years. He knows the application like the back of his hand. He's the go-to guy for all those questions about how the most ancient features behave. He knows there's no way the company will let him go; he knows too much! So he doesn't feel like there's any reason to learn new skills. What he knows has served him just fine so far. Who needs to waste time after work learning the latest programming language or the newest testing tool?
6. Conference Connie:
Connie is so excited about tech! She loves to hear about the latest testing techniques and the latest development trends. She signs up for webinars, goes to conferences, reads blog posts, and takes courses online. She knows a little about just about everything! But she's never actually implemented any of the new things she learns. She's so busy going to conferences and webinars that she barely has time to do her regular testing tasks. And besides, trying things out is a lot of work. It's easier to just see how other people have done it.
What Jim and Connie have in common:
Jim and Connie seem like total opposites at first: Jim doesn't want to learn anything new, and Connie wants to learn everything new. But they actually have the same problem: they are not growing as testers. Jim is content to do everything he's already learned, and doesn't see any reason to learn anything more. But he could be in for a shock one day if his company decides to rewrite the software and he suddenly needs a new skill. And Connie has lots of great ideas, but great ideas don't mean anything unless you actually try them out. Her company isn't benefiting from her knowledge because she's not putting it to use.
How not to be Jim or Connie:
It's important to keep your testing skills fresh by learning new languages, tools, and techniques. You don't have to learn everything under the sun; just pick the things that you think would be most beneficial to your current company, learn them, and then try to implement them in one or two areas. Your teammates will be thankful for the new solutions you introduce, and you'll be developing marketable skills for your next position.
Be a great tester, not a persona!
We all become some of these personas now and then. But if we can be aware of them, we can catch ourselves if we start to slip into Automation Annie or Rabbit Hole Ray, or any of the others. Great testers learn their application better than anyone else, they make good choices about what to test and when, and they keep their skills updated so their testing keeps getting better.
Saturday, April 25, 2020
Book Review: Continuous Testing for DevOps Professionals
For this month's book review, I read Continuous Testing for DevOps Professionals: A Practical Guide from Industry Experts, by various authors and edited by Eran Kinsbruner. The book is divided into four sections: Fundamentals of Continuous Testing, Continuous Testing for Web Apps, Continuous Testing for Mobile Apps, and The Future of Continuous Testing.

The Fundamentals of Continuous Testing section was my favorite, because it focused the most on developing a good Continuous Testing strategy and the elements required. In Continuous Testing for Web Apps, strategies for testing Responsive Web Applications (RWAs) and Progressive Web Applications (PWAs) were discussed, along with cross-browser testing strategies. In Continuous Testing for Mobile Apps, chapters included strategies for testing React Native apps and chatbots, as well as tips for using tools like Appium, Espresso, and XCUITest. Finally, The Future of Continuous Testing took a look at the uses of AI for continuous testing, as well as strategies for testing IoT-enabled devices and Over-the-Top devices.

Since this book obviously covered a lot of ground, I'll focus on my favorite section, Fundamentals of Continuous Testing. Contributor Yoram Mizrachi says there are three types of automated testing failures: test code issues; test lab problems, such as an unstable test environment; and execution problems, such as not enough platforms available to run the tests. There has been much written about solving test code issues, but not enough about solving environment and execution problems, so I was happy to see the suggestions in this book. To solve environment problems, Brad Johnson suggests using containers such as Docker and Kubernetes to spin up environments for testing. Because these environments are temporary, they can be completely controlled in terms of data and application state, so there's less chance of test failures due to environment problems. And Genady Rashkovan offers a solution for execution problems through setting up an automatic detection system for system failures. After gathering initial data, this detection system can be programmed to predict when failures are about to happen, and execute an automatic reboot or spin up a new VM to mitigate a failure before it happens.
I also found Tzvika Shahaf's chapter on using smart reporting very insightful. He notes that test data reporting is often siloed: reports on UI tests use a different format from the reports on API tests, which are in turn different from the reports on performance tests, and so on. This makes it very difficult for managers to get a sense of the health of the application. Shahaf recommends creating a unified report for all tests using this process: tag events so they can be easily identified, normalize the test data so it can be used by a single report, correlate events so similar tests are grouped together, and finally display the events with relevant artifacts. He advises reducing the noise of defects by determining what the most common causes are for test failures and removing the failures that are false negatives. For example, a test failure that was caused by the test environment going down does not actually indicate that something has gone wrong with the software, so a test report designed to show whether new code is working correctly doesn't need to display those failures.
I recommend Continuous Testing for DevOps Professionals for anyone who is working on creating a continuous testing system for their application. There are suggestions for test automation strategies, solving common mobile automation problems, testing connected devices, creating reliable test data, and much more. My one complaint about the book was that the Kindle version was formatted poorly: the chapter divisions were unclear, there were often footnotes in the middle of the page, and diagrams were broken into pieces over two or more pages. For that reason, you may want to purchase a paper copy of the book. But in spite of these problems, I found the book to be very valuable.
Saturday, April 18, 2020
Debugging for Testers
Wikipedia defines debugging as "the process of finding and resolving defects or problems within a computer program that prevent correct operation of computer software or a system". Often we think of debugging as something that only developers need to do, but this isn't the case. Here are two reasons why: first, investigating the cause of a bug when we find it can help the developer fix it faster. Second, since we write automation code ourselves, and since we want to write code that is of high quality just as developers do, we ought to know how to debug our code.

Let's take a look at three different strategies we can employ when debugging code.
Console output:
Code that is executing in a browser or on a device generally outputs some information to the console. You can easily see this by opening up Developer Tools in Chrome or the Web Console in Firefox. When something goes wrong in your application, you can look for error messages in the console. Helpful error messages like "The file 'address.js' was not found" can tell you exactly what's going wrong.
Often an error in an application will produce a stack trace. A stack trace is simply a series of error statements that go in order from the most recent file that was called all the way back to the first file that was called. Here's a very simple example: let's say that you have a Node application that displays cat photos. Your main app.js page calls a function called getCats which will load the user's cat photos. But something goes wrong with getCats, and the application crashes. Your stack trace might look something like this:
Error: cannot find photos
at getCats.js 10:57
at app.js 15:16
at internal/main/run_main_module.js:17:47
Stack traces are often longer, harder to read, and more complicated than this example, but the more you practice looking at them, the better you will get at finding the most important information.
Logging:
Much of what you see in the console output can be called logging, but there are often specific log entries set up in an application's code that record everything that happens in the application. I'm fortunate to work with great developers who are adept at creating clear log statements that make it easy to figure out what happened when things go wrong.
Log statements often come with different levels of importance, such as Error, Warning, Info, and Debug. An application can sometimes be set to only log certain levels of statement. For example, a Production version of an application might be set to only log Errors and Warnings. When you're investigating a bug, it may be possible to increase the verbosity of the logs so you can see the Info and Debug statements as well.
You can also make your own log statements, simply by writing code that will output information to the console. I do this when I'm checking to make sure that my automation code is working like I'm expecting it to. For example, if I had a do-while statement like this:
do {
counter++
}
while (counter < 10)
I might add a logging statement that tells me the value of counter as my program progresses:
do {
console.log ("The value of counter right now is: " + counter)
counter++
}
while (counter < 10)
The great thing about creating your own log statements is that you can set them up in a way that makes the most sense to you.
Breakpoints:
A breakpoint is a place that you set in the code that will cause the program to pause. Software often executes very quickly and it can be hard to figure out what's happening as you're flying through the lines of code. When you set a breakpoint, you can take a look at exactly what all your variable values are at that point in the program. You can also step through the code slowly to see what happens at each line.
Debuggers are generally available in any language you can write code in. Here are some examples:
I hope this post helps you get started with both debugging your code, and investigating someone else's bugs!

Let's take a look at three different strategies we can employ when debugging code.
Console output:
Code that is executing in a browser or on a device generally outputs some information to the console. You can easily see this by opening up Developer Tools in Chrome or the Web Console in Firefox. When something goes wrong in your application, you can look for error messages in the console. Helpful error messages like "The file 'address.js' was not found" can tell you exactly what's going wrong.
Often an error in an application will produce a stack trace. A stack trace is simply a series of error statements that go in order from the most recent file that was called all the way back to the first file that was called. Here's a very simple example: let's say that you have a Node application that displays cat photos. Your main app.js page calls a function called getCats which will load the user's cat photos. But something goes wrong with getCats, and the application crashes. Your stack trace might look something like this:
Error: cannot find photos
at getCats.js 10:57
at app.js 15:16
at internal/main/run_main_module.js:17:47
- The first line of the stack trace is the error- the main cause of what went wrong.
- The next line shows the last thing that happened before the app crashed: the code was executing in getCats.js, and when it got to line 10, column 57, it couldn't find the photos.
- The third line shows which file called getCats.js: it was app.js, and it called getCats at line 15, column 16.
- The final line shows what file was called to run app.js in the first place: an internal Node file that called app.js at line 17, column 47.
Stack traces are often longer, harder to read, and more complicated than this example, but the more you practice looking at them, the better you will get at finding the most important information.
Logging:
Much of what you see in the console output can be called logging, but there are often specific log entries set up in an application's code that record everything that happens in the application. I'm fortunate to work with great developers who are adept at creating clear log statements that make it easy to figure out what happened when things go wrong.
Log statements often come with different levels of importance, such as Error, Warning, Info, and Debug. An application can sometimes be set to only log certain levels of statement. For example, a Production version of an application might be set to only log Errors and Warnings. When you're investigating a bug, it may be possible to increase the verbosity of the logs so you can see the Info and Debug statements as well.
You can also make your own log statements, simply by writing code that will output information to the console. I do this when I'm checking to make sure that my automation code is working like I'm expecting it to. For example, if I had a do-while statement like this:
do {
counter++
}
while (counter < 10)
I might add a logging statement that tells me the value of counter as my program progresses:
do {
console.log ("The value of counter right now is: " + counter)
counter++
}
while (counter < 10)
The great thing about creating your own log statements is that you can set them up in a way that makes the most sense to you.
Breakpoints:
A breakpoint is a place that you set in the code that will cause the program to pause. Software often executes very quickly and it can be hard to figure out what's happening as you're flying through the lines of code. When you set a breakpoint, you can take a look at exactly what all your variable values are at that point in the program. You can also step through the code slowly to see what happens at each line.
Debuggers are generally available in any language you can write code in. Here are some examples:
- Python uses the pdb library
- Javascript uses the debugger statement
- Powershell uses breakpoints in the Powershell ISE
- C# has all kinds of debugging tools in Visual Studio
- Java has debugging tools in Eclipse and IntelliJ
I hope this post helps you get started with both debugging your code, and investigating someone else's bugs!
Saturday, April 11, 2020
The Joy of JWTs
Have you ever used a JWT before? If you have tested anything with authentication or authorization, chances are that you have! The term JWT is pronounced "jot" and it stands for JSON Web Token. JWTs are created by a company called Auth0, and their purpose is to provide a method for an application to determine whether a user has the credentials necessary to request an asset. Why are JWTs so great? Because they allow an application to check for authorization without passing in a username and password or a cookie. Requests of all kinds can be intercepted, but a JWT contains non-sensitive data and is encrypted, so intercepting it doesn't provide much useful information. (For more information about the difference between tokens and cookies, see this post.) Let's learn about how JWTs are made!

A JWT has three parts, which are made up of a series of letters and numbers and are separated by periods. One of the best ways to learn about JWTs is to practice using the official JWT Debugger, so go to jwt.io and scroll down until you see the Debugger section.
Part One: Header
The header lists the algorithm that is used for encrypting the JWT, and also lists the token type (which is JWT, of course):
{
"alg": "HS256",
"typ": "JWT"
}
Part Two: Payload
The payload lists the claims that the user has. There are three types of claims:
Registered claims: These are standard claims that are predefined by the JWT code, and they include:
iss (issuer)- who is issuing the claim
iat (issued at)- what time, in Epoch time, the claim was issued
exp (expiration time)- what time, in Epoch time, the claim will expire
aud (audience)- the recipient of the token
sub (subject)- what kinds of things the recipient can ask for
Public claims: These are other frequently-used claims, and they are added to the JWT registry. Some examples are name, email, and timezone.
Private claims: These are claims that are defined by the creators of an application, and they are specific to that company. For example, a company might assign a specific userId to each of their users, and that could be included as a claim.
Here's an example used in the jwt.io Debugger:
{
"sub": "1234567890",
"name": "John Doe",
"iat": 1516239022
}
Here the subject is 1234567890 (which isn't a very descriptive asset), the name of the user who has access to the subject is John Doe, and the token was issued at 1516239022 Epoch time. Wondering what that time means? You can use this Epoch time converter to find out!
Part Three: Signature
The signature takes the first two sections and encodes them in Base64. Then it takes those encoded sections and adds a secret key, which is a long string of letters and numbers. Finally it encrypts the entire thing with the HMAC SHA256 algorithm. See my post from last week to understand more about encoding and encryption.
Putting It All Together
The JWT is comprised of the encoded Header, then a period, the encoded Payload, then another period, and finally the encrypted signature. The JWT Debugger helpfully color-codes these three sections so you can distinguish them.
If you use JWTs regularly in the software you test, try taking one and putting it in the JWT Debugger. The decoded payload will give you insight into how your application works.
If you don't have a JWT to decode, try making your own! You can paste values like this into the Payload section of the Debugger and see how the encrypted JWT changes:
{
"sub": "userData",
"userName": "kjackvony",
"iss": 1516239022,
"exp": 1586606340
}
When you decode a real JWT, the signature doesn't decrypt. That's because the secret used is a secret! But because the first and second parts of the JWT are encoded rather than encrypted, they can be decoded.
Using JWTs
How JWTs are used will vary, but a common usage is to pass them with an API request using a Bearer token. In Postman, that will look something like this:
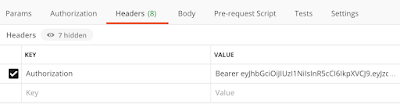
Testing JWTs
Now that you know all about JWTs, how can you test them?
Have fun, and happy testing!

A JWT has three parts, which are made up of a series of letters and numbers and are separated by periods. One of the best ways to learn about JWTs is to practice using the official JWT Debugger, so go to jwt.io and scroll down until you see the Debugger section.
Part One: Header
The header lists the algorithm that is used for encrypting the JWT, and also lists the token type (which is JWT, of course):
{
"alg": "HS256",
"typ": "JWT"
}
Part Two: Payload
The payload lists the claims that the user has. There are three types of claims:
Registered claims: These are standard claims that are predefined by the JWT code, and they include:
iss (issuer)- who is issuing the claim
iat (issued at)- what time, in Epoch time, the claim was issued
exp (expiration time)- what time, in Epoch time, the claim will expire
aud (audience)- the recipient of the token
sub (subject)- what kinds of things the recipient can ask for
Public claims: These are other frequently-used claims, and they are added to the JWT registry. Some examples are name, email, and timezone.
Private claims: These are claims that are defined by the creators of an application, and they are specific to that company. For example, a company might assign a specific userId to each of their users, and that could be included as a claim.
Here's an example used in the jwt.io Debugger:
{
"sub": "1234567890",
"name": "John Doe",
"iat": 1516239022
}
Here the subject is 1234567890 (which isn't a very descriptive asset), the name of the user who has access to the subject is John Doe, and the token was issued at 1516239022 Epoch time. Wondering what that time means? You can use this Epoch time converter to find out!
Part Three: Signature
The signature takes the first two sections and encodes them in Base64. Then it takes those encoded sections and adds a secret key, which is a long string of letters and numbers. Finally it encrypts the entire thing with the HMAC SHA256 algorithm. See my post from last week to understand more about encoding and encryption.
Putting It All Together
The JWT is comprised of the encoded Header, then a period, the encoded Payload, then another period, and finally the encrypted signature. The JWT Debugger helpfully color-codes these three sections so you can distinguish them.
If you use JWTs regularly in the software you test, try taking one and putting it in the JWT Debugger. The decoded payload will give you insight into how your application works.
If you don't have a JWT to decode, try making your own! You can paste values like this into the Payload section of the Debugger and see how the encrypted JWT changes:
{
"sub": "userData",
"userName": "kjackvony",
"iss": 1516239022,
"exp": 1586606340
}
When you decode a real JWT, the signature doesn't decrypt. That's because the secret used is a secret! But because the first and second parts of the JWT are encoded rather than encrypted, they can be decoded.
Using JWTs
How JWTs are used will vary, but a common usage is to pass them with an API request using a Bearer token. In Postman, that will look something like this:

Testing JWTs
Now that you know all about JWTs, how can you test them?
- Try whatever request you are making without a JWT, to validate that data is not returned.
- Change or remove one letter in the JWT and make sure that data is not returned when the JWT is used in a request.
- Decode a valid JWT in the Debugger, change it to have different values, and then see if the JWT will work in your request.
- Use a JWT without a valid signature and make sure that you don't get data in the response.
- Make note of when the JWT expires, and try a request after it expires to make sure that you don't get data back.
- Create a JWT that has an issue time of somewhere in the future and make sure that you don't get data back when you use it in your request.
- Decode a JWT and make sure that there is no sensitive information, such as a bank account number, in the Payload.
Have fun, and happy testing!
Subscribe to:
Posts (Atom)
-
 It's book review time once again, and this month I read Unit Testing Principles, Practices, and Patterns by Vladimir Khorikov. I thoug...
It's book review time once again, and this month I read Unit Testing Principles, Practices, and Patterns by Vladimir Khorikov. I thoug... -
 Just over a decade ago, the first iPhone was released. Now we live in an age where smartphones are ubiquitous. Our smartphones are like ou...
Just over a decade ago, the first iPhone was released. Now we live in an age where smartphones are ubiquitous. Our smartphones are like ou... -
 I read a ton of books, and I've found that reading books about testing is my favorite way to learn new technical skills and testing stra...
I read a ton of books, and I've found that reading books about testing is my favorite way to learn new technical skills and testing stra...